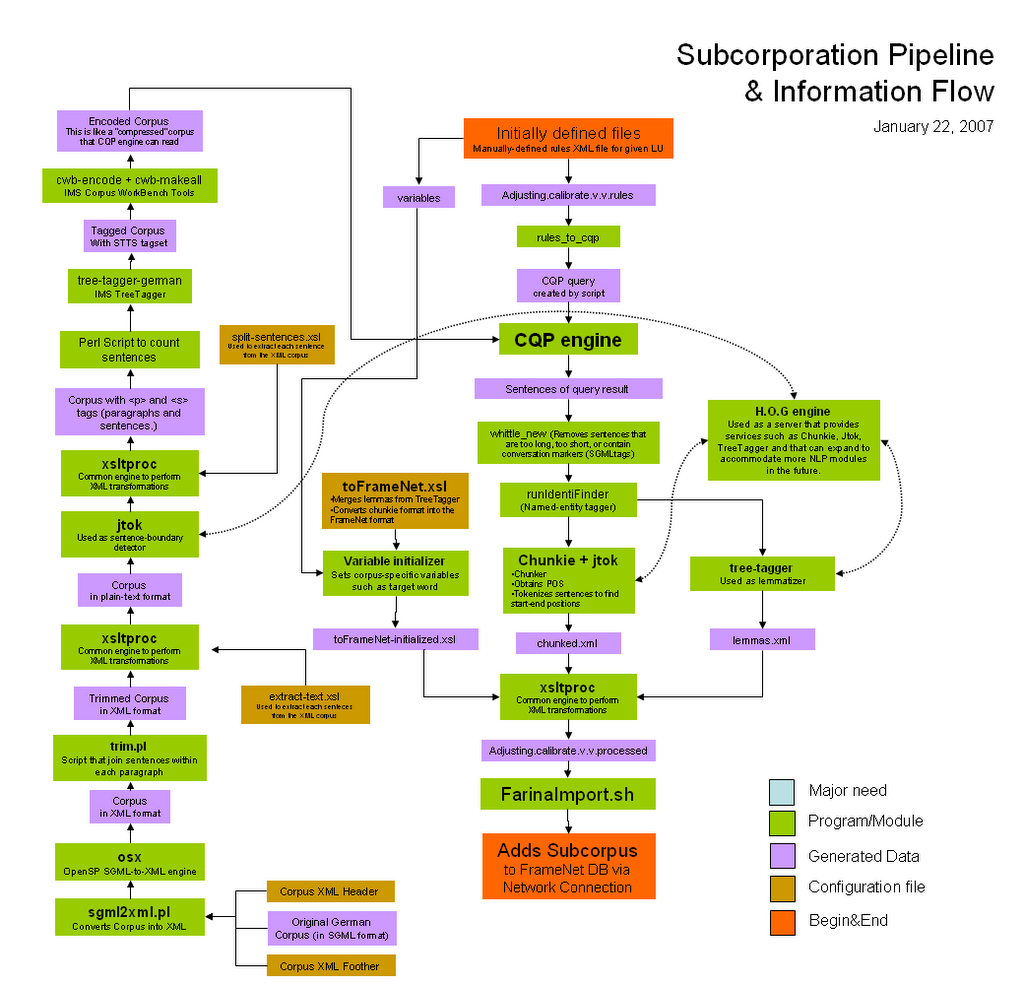
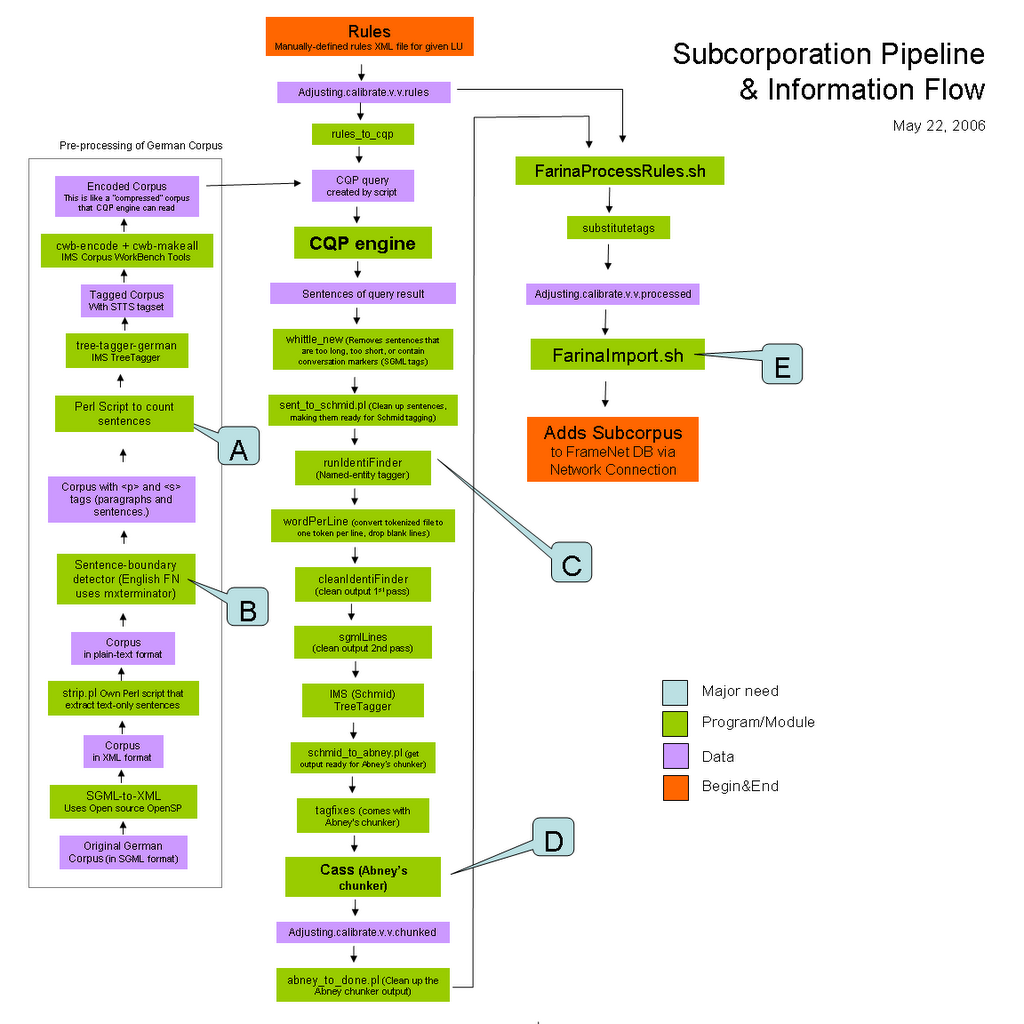
File structure & To-do
The file structure of the German Framenet is currently organized as follows:
Major To-do items:
- current/remote_client/heartofgold/hog Contains the files of the Hear of Gold engine. This includes the chunker and tokenizer. It also includes some of the xsl transformation files such as toFrameNet.xsl
- current/remote_client/german-client Includes client utils such as FnDesktop
- current/german German version of the FN database
- current/english English version of the FN database
- current/fnSystem Complete FN database and JBoss that Jisup emailed to us
- current/corpus corpus files including:
- bin utils
- cfg some scripts and config files such as header/footers & DTD files
- cqp CQP engine version 3.0
- doc some documentation drafts
- lib includes OpenSP SGML to XML comverter
- other tar files of the original corpora as they came on the CDs
- raw uncompressed corpora (AFP, APWS, DPA)
- tagger IMS tree-tagger
- txt plain-text version of corpora (i.e., without tags)
- xml XML version of the corpora
- current/sandbox misc files
Major To-do items:
- Incorporate the H.O.G. engine
- Solve the FarinaImport.sh error
- Create a few more scripts to plug-in different pipeline components
posted by Mario Guajardo at
6:23 AM
|
1 comments
![]()
![]()