General Pipeline | Pending Parts
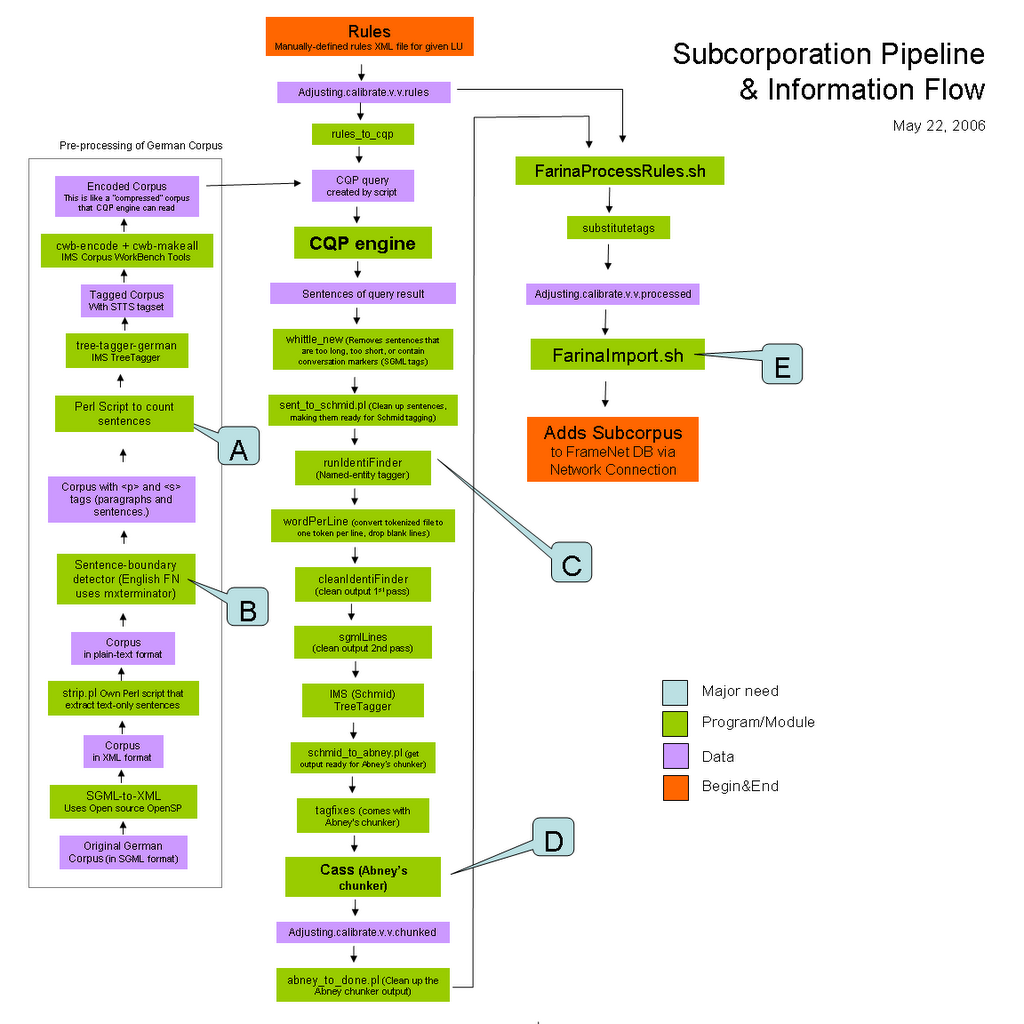
B.
In order to properly import a corpus into CQP, the corpus needs to have "p" XML tags surounding every paragraph and "s" tags surounding every sentence. However, the text contained in the German Corpus contains only "p" tags. Therefore, we have to look for a program that will perform boundary-sentence detection for us in order to add "s" tags. The program mxterminator is used as boundary-sentence detector for the English FN.
A.
Eventually, every sentence that will be imported into FN will need to have some ID assigneed to the sentence. However, these IDs are not part of the original corpus; rather, a (Perl) script was written for the English FN which takes an entire corpus and outpus the same corpus, but now with an ID prepended to each sentence. A sample ID along with its sentence looks as follows: apwsE941117.0373=1=7=1 A sample sentence. Where, after being transformed by intermediate scripts, the ID information will be written to the final XML file given to FarinaImport.sh as this: docInfo="apwsE941123.0183" textNo="1" paraNo="7" sentNo="1" Either we can ask Collin to send this script to us so that we can reuse it or we can write a similar script.
C.
A named-entity tagger is a program that takes a sentence as input and identifies (tags) the part of the sentences belonging to an entity. Entities can be proper names, names of cities and places, names of companies, countries, etc. Here the task is to search the Internet for either an open-source or a commercial named-entity tagger for German. (In an intial phase, this part of the pipeline may be skipped at the expense that annotators will have to manually detect entities during the annotation process.)
D.
Chunker
Since for the English FN, Abney's chunker produces an ouput as follows:
[nmess lemma=
h=[nx lemma=
h=[person
[nnp lemma=Prince Prince]
[person lemma=Philip Philip]]]]
[vvd lemma=lament
[comp lemma=that that]
[nil lemma=`` ``]
[nmess lemma
...
and since our IMS chunker for German produces an output as follows:
Eine ART
weitere ADJA
Schwierigkeit NN
</NC>
<VC>
besteht VVFIN
</VC>
darin PAV
, $,
daß KOUS
<NC>
die ART
Kameras NN
</NC>
nur ADV
dann ADV
<NC>
verwertbares ADJA
Bildmaterial NN
</NC>
<VC>
liefern VVFIN
</VC>
, $,
wenn KOUS
<NC>
die ART
See NN
</NC>
einigermaßen ADV
ruhig ADJD
<VC>
ist VAFIN
</VC>
. $.
Here, the task is to take the ouput of the IMS chunker for German and convert it to the format produced by Abney's chunker for English. Another approach could be to find a chunker for german that already produces its output in the same format as Abney's.
As a last resource, this stage of the pipeline may be skipped intially, but the burden to do so might suggest that is better to avoid skipping it. In case it is to be skipped, we would have to modify the existing Java classes of FrameNet, remove all references that invoke in ProcessRules.sh that filter the sentences (given some rules), and keep only the functions that add the (now unfiltered) sentences into the FN database. Again, this seems to complex that is not recommended.
E.
Assuming we have succesfully obtained an XML file containing subcorpora that is ready to be added to FN's database. For this task, we need to use FarinaImport.sh script.
However, by using a sample XML file we could not import the sample subcorpora into the German FN, FarinaImport.sh produced a Java exception the cause of which we could not find (see the previous blog entry for details.)
Both Collin and Marc Ortega (from the SpanishFN) helpmed me debug this problem but we had no success. Not to say that there is no solution, but because of time constrains we did not find the solution.
Given the follwing (simplistic) sample XML subcorpus:
<?xml version="1.0" encoding="UTF-8"?>
<subcorpora frame="Adjusting" lexunit="calibrate.v" lemma="calibrate" pos="V">
<annoset-conf classify-type="fn2.farina.classify.FNClassifierPenn">
<annoset-model type="POS">
<layer-model containsPOS="y">PENN</layer-model>
</annoset-model>
<annoset-model type="standard">
<layer-model>Target</layer-model>
<layer-model>FE</layer-model>
<layer-model>GF</layer-model>
<layer-model>PT</layer-model>
<layer-model>Other</layer-model>
<layer-model>Sent</layer-model>
</annoset-model>
</annoset-conf>
<subcorpus scName="02-T-NP-PPto" maxSize="20">
<s tStart="0" tEnd="11" aPos="7382282" corpus="BNC2" docInfo="bncp" textNo="372" paraNo="162" sentNo="9">
<!--
<text>calibrated .</text>
<words>
<w pos="VVN" wf="calibrated" target="y" start="0" end="9">calibrate</w>
<w pos="SENT" wf="." start="11" end="11">.</w>
</words>
-->
<text>.</text>
<words>
<w pos="SENT" wf="." start="0" end="0">.</w>
</words>
<labels>
</labels>
</s>
</subcorpus>
</subcorpora>
This is what we tried:
- We noted that adding an empty subcorpus worked succesfully. That is, FarinaImport.sh was able to properly add a record to the SubCorpus table. This means that FarinaImport.sh succesfully communicates with the German FN database.
- As soon as we included a corpus with at least one "w" tag, the given Java exception was thrown. This is the misterious part, the reason of which we would not figure out.
- Though we rapidly verified the records in MiscLabel and LabelType tables, correspoding to the Penn stagset (yes, our sample file uses the Penn tagset and it is still pending adding the German STTS tagset into these tables.) At a first glance, it seemed that these tables had correct information. However, going over the records of this tables and corroborating that they have correct values for the tags involved in the example, will be an starting point to debug.
- We manually added records to the tables Corpus and Document as we were unsure whether FarinaImport.sh will add initial records to this tables when these tables are empty. It did not make a difference as the Java exception was still thrown.
- Marc sent me a new version of the Client and Server parts of the original English FN. I tried the client part and the Java error still appeared. I tried to configure the server part with the new release but I could not configure it properly. Elias might now how to do so.
- I tried both adding the sample file to both our English and our German versions of FN and both threw the same Java exception.
- From within FNDesktop, I tried assigning diffferent statuses for the given LU and it made no difference.
Other parts
Most of the scripts of the remaining part of the diagrams have not been tested and some of them may require some changes. It is important to note that it will be very advisable to review the script FN2Import.sh as it is the "mother" script that calls all the part of the middle column of the diagram.
Thanks a lot to Collin and Marc for all of their invaluable help and cooperation.
posted by Mario Guajardo at
7:55 AM
![]()
![]()

0 Comments:
Post a Comment
<< Home